The Simpsons has a rich cast of great characters, with Wikipedia suggesting the show has somewhere around 100 recurring characters. But, outside the titular family members, who can claim to be the main side character in the show? I’m not interested in who the best character is—because let’s face it, we all know it’s Roy—but which character plays the biggest role in the show.
I approached this by checking which characters are featured in Wikipedia’s description of each episode. The aim here is to identify characters who impacted the plot of an episode in some sense, as opposed to characters who merely appeared in the episode. This isn’t a perfect measure—the very first episode lists a number of characters simply due to it being their first appearance—but it should be a good proxy.
If you’re interested in how I got the data and would like to learn a little about how to do so yourself read on, otherwise you can skip straight to the results.
Scraping the data
This whole exercise was born out of an interest in learning about scraping data from the web using the R package rvest. As such, I’ve almost certainly not done this in the most efficient manner. I’m sure there are Simpsons fan sites who have listings of which episodes characters have appeared in, but for me this is more an exercise in gathering data from webpages.
My approach was:
- Get the URLs for the Wikipedia page of all Simpsons episodes
- From these webpages, extract the main body of text describing the episode
- From this text, extract all words with a capital letter (which should be names)
- Clean this text of non-names and find which characters appear most frequently
Get the URLs of Wikipedia pages of all Simpsons episodes
Wikipedia has a page listing all episodes of The Simpsons (seasons 1-20). We can use read_html() to read in the contents of this page and html_nodes to extract specific pieces from this HTML. Using the CSS Selector gadget we can identify this piece of the page as .summary a. From this, we can get the URL target using html_attr to search for the href tag.
library(rvest)
# Wikipedia page containing links to all Simpsons episodes seasons 1-20
url <- "https://en.wikipedia.org/wiki/List_of_The_Simpsons_episodes_(seasons_1%E2%80%9320)"
# Grab a list of all the episode URLs
episode_urls <- read_html(url) %>%
html_nodes(".summary a") %>%
html_attr("href")
If you’re unfamiliar with the pipe operator, a %>% b, it simply passes the output of a into the first argument b. So, (2 + 2) >%> sqrt would evaluate as sqrt(4) = 2.
Get the main body of text from the Wiki page
Now with the list of URLs we can iterate through each page and extract the main body of text, by targetting the node p.
# Follow the episode link
synopsis <- read_html(paste("https://en.wikipedia.org", episode_url, sep = "")) %>%
html_nodes("p") %>%
html_text()
Extract all proper nouns
In order to get the names of characters mentioned in the Wikipedia page I started by just grabbing all the capitalised words from the text. However, there are few bits to clean up first. We want to get rid of any non-alpha text. To do this, we use gsub to search for non-alpha text using the regular expression [^a-zA-Z] and replace them with the letter ‘z’ surrounded by spaces. I did this to put a boundary between words which were neighbours across two sentences. I then split the text into individual words to make it easier to search.
synopsis <- gsub("[^a-zA-Z ]", " z ", synopsis)
synopsis <- paste(synopsis, collapse = " ") %>%
strsplit(split = " ") %>%
.[[1]]
As we’re only interested in character names, we can extract all words which have a capital letter in them using grep and the regular expression [A-Z] to search for words containing capital letters.
# Identify wods with a capital letter
ind <- grep("[A-Z]", synopsis)
# Extract just the capitalised words
synopsis <- synopsis[ind]
Since many of the characters will be referred to using their whole names, I then identified cases where two adjacent words were capitalised and merged them. This isn’t a guaranteed fix, as adjacent words can be capitalised for reasons other than it being a forename surname combination. (This is why I replaced non-alpha characters with “ z “, as the ‘z’ now acts as a boundary between proper nouns which might’ve been part of a list or simply situated at the end/beginning of neighbouring sentences.)
# Check if two adjacent words are capitalised
merge_ind <- ind[2:length(ind)] - ind[1:(length(ind) - 1)] == 1
# If two adjacent words are capitalised we'll merge them
for(i in length(synopsis):2) {
if(merge_ind[i - 1]) {
synopsis[i - 1] <- paste(synopsis[i - 1], synopsis[i], sep = " ")
synopsis[i] <- ""
}
}
Next I get rid of blank spaces created from the above and then got rid of duplicate values.
synopsis <- synopsis[synopsis != ""] # Get rid of blanks
synopsis <- unique(synopsis) # Remove duplicates
With that done, the process so far needs to be repeated for all other episodes. I looped over all 441 episodes using a for loop; I’d usually include a Sys.sleep() within the loop so I’m not bugging the web host too frequently.
Text processing
Although we’ve extracted all the proper nouns, most of them aren’t what we’re looking for. Unfortunately, processing the text is a little more manual than the other steps so far. I used sort and table to get an idea of which names tended to be appearing most frequently and made a list of commonly-occurring, irrelevant words—mostly the creators, the cast, months, “Fox”, “Emmy” etc—and got rid of those. I then used grep to find variations on common characters names, as follows:
gsub(".*Moe.*","Moe", synopsis)
This will find any cases where we have “Moe”, e.g. “Moe Szyslak”, “Moe’s Tavern”, and convert them to just say “Moe”, making tabulating names a little easier. Figuring out which of these to do really just required searching through the top list and finding common variations of the main characters, relying a little on my Simpsons knowledge too.
Results
After much cleaning I managed to get a settled top 20 list for most frequently appearing side characters. I created a plot of the data using the ggplot2 package, making some theme modifications to make it look Simpsons-y.
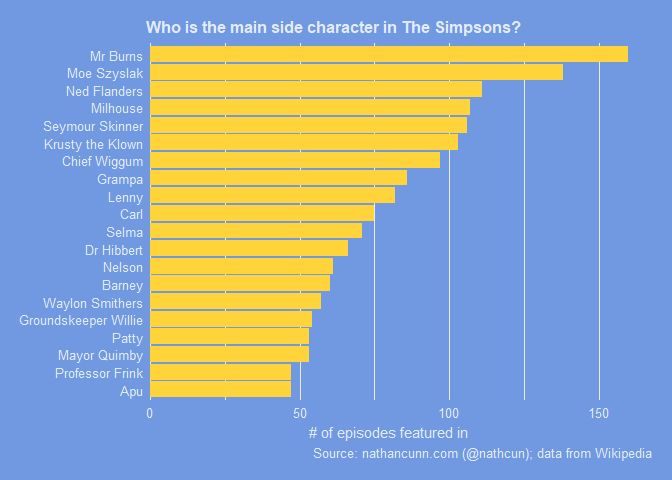
It turns out Mr Burns is the winner with Moe following reasonably close behind. I guess it helps that these characters are associated with the regular hangouts of the main character, Homer. Of all the Simpsons episodes I looked at, only ten of them don’t mention Homer. I say only, I’m actually surprised any episode could not have Homer as an important enough character to mention in the Wikipedia description. These episodes do exist though. Bart, the next most frequently mentioned character, was absent in just over 50 episodes. Interestingly, given I’d imagine Bart is considered a much more important character in the show, Marge is mentioned in only one fewer episode than Bart. Again, this could be due to her centrality to Homer’s plot lines.
Other interesting things to note: Lenny is slightly more prominent than Carl but the two are pretty much a package deal. Patty and Selma on the other hand aren’t as much of a package as you might expect, with Selma placing six places higher than her twin sister. Selma is the sister who married both Sideshow Bob and Troy McClure (and apparently Fat Tony, Lionel Hutz, Disco Stu, and Abraham Simpson) and has also dated Moleman, who is sadly missing from the list.
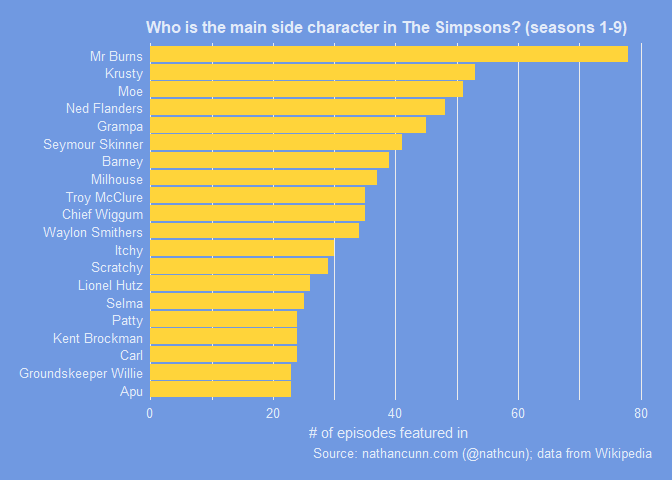
If we restrict the episode list to just seasons 1-9, the peak Simpsons episodes, a few of the classic characters appear: Lionel Hutz, Troy McClure, Itchy and Scratchy, Kent Brockman. Troy McClure and Lionel Hutz were arguably two of the most popular recurring characters in the show but were written out of it in season ten following Phil Hartman’s tragic death. However, even when we restrict it to only look at the classic episodes, there’s only one character standing out amongst all others: Mr Burns.